
- Details
This functionality provides many opportunities for increasing accuracy of calculations while using less computational resources.
For your tasks, you can use:
- volume / surface adaptation;
- adaptation for curvature / sharp edges;
- adaptation by condition / to solution;
- merging.
- Details
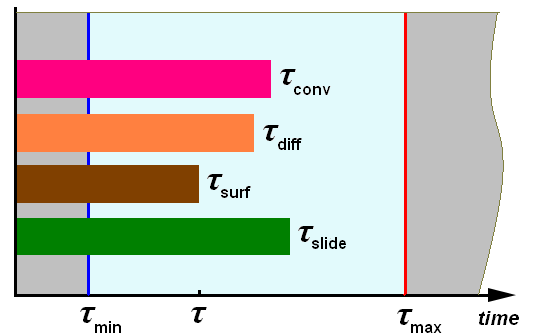
To solve a numerical task, it is necessary to discretize space and time. A time scale allows to find intermediate solutions based on the initial and boundary conditions. Gradually coming through the intermediate solutions, we get the final one, which we can use to achieve the goals: choosing the right paint for the rocket skin, calculating the flow rate of your favorite ketchup, or getting the optimal washing temperature for a cat.
The intervals at which software calculates a solution are commonly referred to as the time step. It can be constant or calculated for each iteration based on a certain criteria. It should be noted that the time step is different for each specific software and task.
How to specify it correctly - we will describe in this article.

- Details
You can use formulas in FlowVision to set any variable: from the gravity vector to the law of a moving body motion. All this became possible with the formula Editor. Using the formula Editor you may calculate composite functions, set the physical laws of variable changings and even set the level of adaptation for the calculation grid depending on the step number (and much more!).
In this article we will show how this functionality can significantly simplify the user's life.
- Details
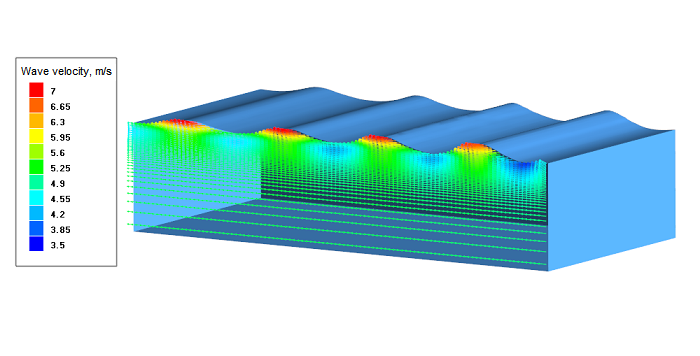
Now it's easier to simulate sea waves in FlowVision!
You may set complex boundary conditions for the formation of natural gravitational waves using the formula editor. But these formulas are quite complex. Therefore, we used the computational engineering platform API and connected this module to FlowVision, so it became convinient to create user boundary conditions which generate waves.
- Details
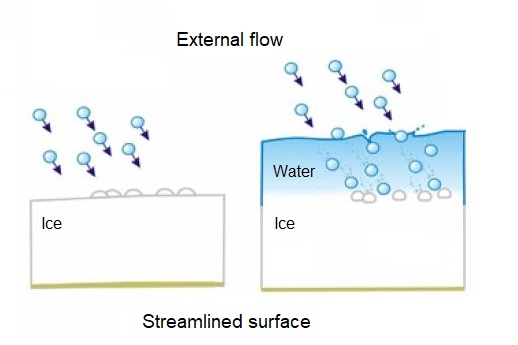
For FlowVision 3.12.01 release we made a breakthrough in the development of processes in dispersed phases. As a result, it became possible to simulate the icing of surface. Today you can apply the both icing modes to your tasks - dry icing mode and wet one. What is the difference between these modes? How to simulate icing processes correctly? What results will be obtained in FlowVision? You will find all answers in this article.
- Details
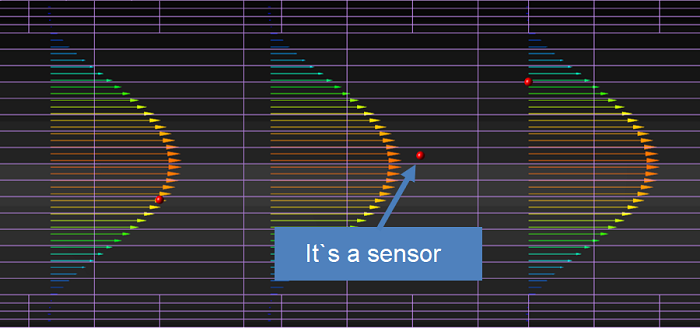
A set of sensors is a measuring object which can be placed anywhere in the calculation domain.
Previously, to obtain a variable at a certain point of computational domain, it was necessary to create a small object with dimentions closed to the cell size and set a characteristic on this object. It became much more convenient with the help of sensors. You can simply select a point or even several points in space, create there the sensor set and receive data in one glo-file.
- Details
You have started a simulation of physical processes in Flow Vision by yourself, but the calculation always breaks down. Or the calculation runs, but the results do not correspond to physics. Is it familiar to you? Here is the quintessence of the experience from technical support and the training department staff. It`s a guide on what to do if your calculation breaks down.

- Details
To obtain the exact solution in numerical simulation, the reference values should be set correctly. Find out from this article how to set the reference values and how they affect the accuracy of the solution. We also examined two cases that our users usually face. Forewarned is forearmed.
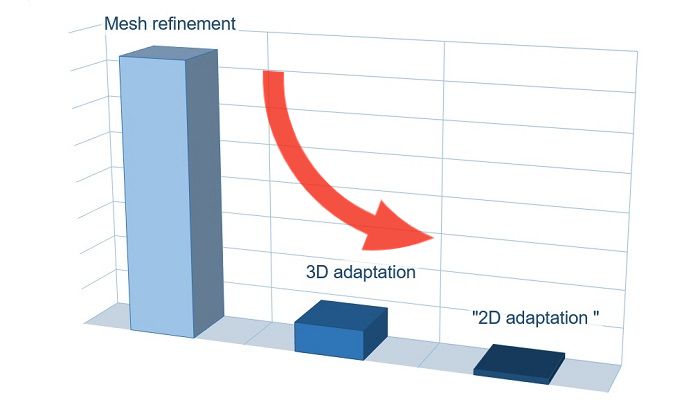
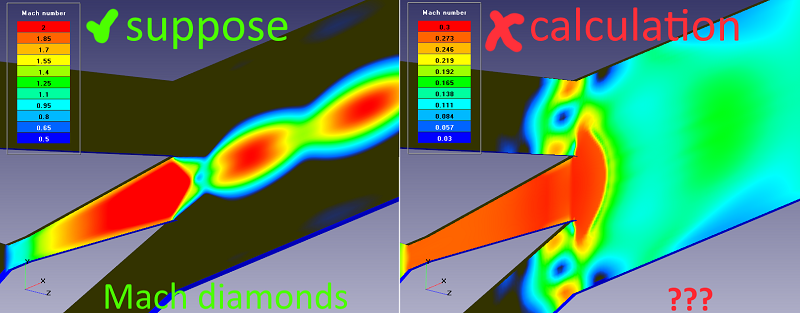
- Details
Today we will talk about minimization of the computational mesh in a two-dimensional calculation. In general, FlowVision is a three-dimensional CFD software. But the 3D calculation becomes 2D if there is only one calculation cell in one direction. Unfortunately, two-dimensionality disappears when adaptation is enabled. User of FlowVision from JIHT figured out this issue.

- Details
Sometimes the situations appear, when the co-simulation may be interrupted for a number of reasons:
1. Lack of memory (both operational and physical);
2. Restarting the machine on which the calculation has been carried out.
3. The necessity to stop the calculation for project modification.
If the simulation is carried out only in FlowVision, the problem is easily solved by continuing the simulation from the last save. In the case of a joint simulation, the procedure is more complicated.
- Details
FlowVision uses floating type of license. It means:
- The license is installed and attached to one computer and can’t be transferred or registered on another computer;
- But users can work with FlowVision on any computer and they can even constantly change their working computer. FlowVision will request a license from the computer on which the license was registered.
- On one computer it’s possible to register many licenses for different users. It allows to avoid blocking license, for example, of the user of neighboring department.
- You can also register one general license, for example, with a large number of cores and allow users to compete for licenses :) This allows you to run the calculation on the maximum number of cores if necessary.
Thus it is convenient for a company to allocate a server for registering and storing a license instead of, for example, a laptop.

- Details
When modeling a physical phenomenon, the most informative way of visualization is video.
In this article, we will describe how to turn a sequence of images into a video clip.